Note
Go to the end to download the full example code.
Fine-tuning TabICL for regression#
Adapt a pretrained TabICL regressor to a single dataset with
tabicl.FinetunedTabICLRegressor (pinball loss on raw quantiles,
same objective the pretrained head was fit with).
Note
A CUDA GPU is recommended for large-scale fine-tuning. Multi-GPU via
torchrun --nproc-per-node=N (auto-detected).
import os
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from tabicl import FinetunedTabICLRegressor, TabICLRegressor
Target: one easy feature (sine), one hard feature (spike)#
def target_fn(x: np.ndarray) -> np.ndarray:
return 0.8 * np.sin(1.2 * x) + 2.5 * np.exp(-80.0 * (x - 1.0) ** 2)
def make_dataset(n_samples: int = 1_000, random_state: int = 0):
rng = np.random.RandomState(random_state)
x = rng.uniform(-3.0, 3.0, size=n_samples)
y = target_fn(x) + rng.normal(0.0, 0.08, size=n_samples)
X = x.reshape(-1, 1).astype(np.float32)
return X, y.astype(np.float32)
X, y = make_dataset(n_samples=1000, random_state=0)
# Split: 40 train (sparse at the spike) / 200 val (early stopping) / 760 test.
X_train, X_rest, y_train, y_rest = train_test_split(X, y, train_size=40, random_state=0)
X_val, X_test, y_val, y_test = train_test_split(X_rest, y_rest, train_size=200, random_state=0)
is_main_process = int(os.environ.get("LOCAL_RANK", "0")) == 0
def _metrics(pred: np.ndarray, y_true: np.ndarray) -> tuple[float, float, float]:
return (
float(mean_squared_error(y_true, pred)),
float(mean_absolute_error(y_true, pred)),
float(r2_score(y_true, pred)),
)
Baseline — zero-shot TabICL#
Expected: draws the sine, smears the spike.
base = TabICLRegressor(n_estimators=4, random_state=0)
base.fit(X_train, y_train)
base_pred = base.predict(X_test)
base_mse, base_mae, base_r2 = _metrics(base_pred, y_test)
# Captured for the training-curve reference line in Figure 2.
base_val_mse = float(mean_squared_error(y_val, base.predict(X_val)))
Fine-tune#
_HistoryLogger below is installed via the same
_make_experiment_logger hook wandb_kwargs uses, to capture per-epoch
val metrics for Figure 2 without pulling in W&B.
history: dict[str, list[float]] = {
"epoch": [],
"val_mse": [],
"val_mae": [],
"val_r2": [],
"train_loss": [],
}
class _HistoryLogger:
"""Record per-epoch validation metrics into ``history``."""
def setup(self, config):
del config
def log_step(self, metrics, step):
del metrics, step
def log_epoch(self, metrics, step):
del step
history["epoch"].append(int(metrics.get("train/epoch", len(history["epoch"]))) + 1)
history["val_mse"].append(float(metrics.get("val/mse", np.nan)))
history["val_mae"].append(float(metrics.get("val/mae", np.nan)))
history["val_r2"].append(float(metrics.get("val/r2", np.nan)))
history["train_loss"].append(float(metrics.get("train/mean_loss", np.nan)))
def finish(self):
pass
reg = FinetunedTabICLRegressor(
epochs=60,
learning_rate=1e-5,
n_estimators_finetune=2,
n_estimators_validation=2,
n_estimators_inference=4,
early_stopping=True,
patience=10,
random_state=0,
verbose=True,
)
reg._make_experiment_logger = lambda: _HistoryLogger()
reg.fit(X_train, y_train, X_val=X_val, y_val=y_val)
/home/docs/checkouts/readthedocs.org/user_builds/tabicl/checkouts/latest/tutorials/finetune_regressor.py:120: UserWarning: `output_dir` is not set; no checkpoints will be saved and all fine-tuning progress is lost if the run is interrupted.
reg.fit(X_train, y_train, X_val=X_val, y_val=y_val)
Baseline val mse: -0.0586
Fine-tune: 0%| | 0/60 [00:00<?, ?it/s]
Fine-tune: 0%| | 0/60 [00:01<?, ?it/s, train_loss=0.0817, val_mse=-0.0586, best=-0.0586, s/epoch=0.6]
Fine-tune: 2%|▏ | 1/60 [00:01<01:01, 1.04s/it, train_loss=0.0817, val_mse=-0.0586, best=-0.0586, s/epoch=0.6]
Fine-tune: 2%|▏ | 1/60 [00:01<01:01, 1.04s/it, train_loss=0.1725, val_mse=-0.0588, best=-0.0586, s/epoch=0.4]
Fine-tune: 3%|▎ | 2/60 [00:01<00:53, 1.08it/s, train_loss=0.1725, val_mse=-0.0588, best=-0.0586, s/epoch=0.4]
Fine-tune: 3%|▎ | 2/60 [00:02<00:53, 1.08it/s, train_loss=0.0530, val_mse=-0.0591, best=-0.0586, s/epoch=0.4]
Fine-tune: 5%|▌ | 3/60 [00:02<00:50, 1.13it/s, train_loss=0.0530, val_mse=-0.0591, best=-0.0586, s/epoch=0.4]
Fine-tune: 5%|▌ | 3/60 [00:03<00:50, 1.13it/s, train_loss=0.0999, val_mse=-0.0596, best=-0.0586, s/epoch=0.4]
Fine-tune: 7%|▋ | 4/60 [00:03<00:48, 1.15it/s, train_loss=0.0999, val_mse=-0.0596, best=-0.0586, s/epoch=0.4]
Fine-tune: 7%|▋ | 4/60 [00:04<00:48, 1.15it/s, train_loss=0.0910, val_mse=-0.0595, best=-0.0586, s/epoch=0.4]
Fine-tune: 8%|▊ | 5/60 [00:04<00:46, 1.18it/s, train_loss=0.0910, val_mse=-0.0595, best=-0.0586, s/epoch=0.4]
Fine-tune: 8%|▊ | 5/60 [00:05<00:46, 1.18it/s, train_loss=0.0802, val_mse=-0.0584, best=-0.0584, s/epoch=0.4]
Fine-tune: 10%|█ | 6/60 [00:05<00:45, 1.18it/s, train_loss=0.0802, val_mse=-0.0584, best=-0.0584, s/epoch=0.4]
Fine-tune: 10%|█ | 6/60 [00:06<00:45, 1.18it/s, train_loss=0.0291, val_mse=-0.0573, best=-0.0573, s/epoch=0.4]
Fine-tune: 12%|█▏ | 7/60 [00:06<00:44, 1.19it/s, train_loss=0.0291, val_mse=-0.0573, best=-0.0573, s/epoch=0.4]
Fine-tune: 12%|█▏ | 7/60 [00:06<00:44, 1.19it/s, train_loss=0.0560, val_mse=-0.0561, best=-0.0561, s/epoch=0.4]
Fine-tune: 13%|█▎ | 8/60 [00:06<00:43, 1.19it/s, train_loss=0.0560, val_mse=-0.0561, best=-0.0561, s/epoch=0.4]
Fine-tune: 13%|█▎ | 8/60 [00:07<00:43, 1.19it/s, train_loss=0.0339, val_mse=-0.0554, best=-0.0554, s/epoch=0.4]
Fine-tune: 15%|█▌ | 9/60 [00:07<00:42, 1.20it/s, train_loss=0.0339, val_mse=-0.0554, best=-0.0554, s/epoch=0.4]
Fine-tune: 15%|█▌ | 9/60 [00:08<00:42, 1.20it/s, train_loss=0.5892, val_mse=-0.0573, best=-0.0554, s/epoch=0.4]
Fine-tune: 17%|█▋ | 10/60 [00:08<00:41, 1.21it/s, train_loss=0.5892, val_mse=-0.0573, best=-0.0554, s/epoch=0.4]
Fine-tune: 17%|█▋ | 10/60 [00:09<00:41, 1.21it/s, train_loss=0.0403, val_mse=-0.0591, best=-0.0554, s/epoch=0.4]
Fine-tune: 18%|█▊ | 11/60 [00:09<00:40, 1.22it/s, train_loss=0.0403, val_mse=-0.0591, best=-0.0554, s/epoch=0.4]
Fine-tune: 18%|█▊ | 11/60 [00:10<00:40, 1.22it/s, train_loss=0.0706, val_mse=-0.0608, best=-0.0554, s/epoch=0.4]
Fine-tune: 20%|██ | 12/60 [00:10<00:39, 1.22it/s, train_loss=0.0706, val_mse=-0.0608, best=-0.0554, s/epoch=0.4]
Fine-tune: 20%|██ | 12/60 [00:10<00:39, 1.22it/s, train_loss=0.0553, val_mse=-0.0605, best=-0.0554, s/epoch=0.4]
Fine-tune: 22%|██▏ | 13/60 [00:10<00:38, 1.23it/s, train_loss=0.0553, val_mse=-0.0605, best=-0.0554, s/epoch=0.4]
Fine-tune: 22%|██▏ | 13/60 [00:11<00:38, 1.23it/s, train_loss=0.0446, val_mse=-0.0606, best=-0.0554, s/epoch=0.4]
Fine-tune: 23%|██▎ | 14/60 [00:11<00:37, 1.22it/s, train_loss=0.0446, val_mse=-0.0606, best=-0.0554, s/epoch=0.4]
Fine-tune: 23%|██▎ | 14/60 [00:12<00:37, 1.22it/s, train_loss=0.0243, val_mse=-0.0602, best=-0.0554, s/epoch=0.4]
Fine-tune: 25%|██▌ | 15/60 [00:12<00:36, 1.23it/s, train_loss=0.0243, val_mse=-0.0602, best=-0.0554, s/epoch=0.4]
Fine-tune: 25%|██▌ | 15/60 [00:13<00:36, 1.23it/s, train_loss=0.0596, val_mse=-0.0584, best=-0.0554, s/epoch=0.4]
Fine-tune: 27%|██▋ | 16/60 [00:13<00:35, 1.23it/s, train_loss=0.0596, val_mse=-0.0584, best=-0.0554, s/epoch=0.4]
Fine-tune: 27%|██▋ | 16/60 [00:14<00:35, 1.23it/s, train_loss=0.0641, val_mse=-0.0565, best=-0.0554, s/epoch=0.4]
Fine-tune: 28%|██▊ | 17/60 [00:14<00:34, 1.23it/s, train_loss=0.0641, val_mse=-0.0565, best=-0.0554, s/epoch=0.4]
Fine-tune: 28%|██▊ | 17/60 [00:15<00:34, 1.23it/s, train_loss=0.0693, val_mse=-0.0543, best=-0.0543, s/epoch=0.4]
Fine-tune: 30%|███ | 18/60 [00:15<00:34, 1.23it/s, train_loss=0.0693, val_mse=-0.0543, best=-0.0543, s/epoch=0.4]
Fine-tune: 30%|███ | 18/60 [00:15<00:34, 1.23it/s, train_loss=0.0421, val_mse=-0.0522, best=-0.0522, s/epoch=0.4]
Fine-tune: 32%|███▏ | 19/60 [00:15<00:33, 1.22it/s, train_loss=0.0421, val_mse=-0.0522, best=-0.0522, s/epoch=0.4]
Fine-tune: 32%|███▏ | 19/60 [00:16<00:33, 1.22it/s, train_loss=0.0558, val_mse=-0.0496, best=-0.0496, s/epoch=0.4]
Fine-tune: 33%|███▎ | 20/60 [00:16<00:32, 1.22it/s, train_loss=0.0558, val_mse=-0.0496, best=-0.0496, s/epoch=0.4]
Fine-tune: 33%|███▎ | 20/60 [00:17<00:32, 1.22it/s, train_loss=0.0392, val_mse=-0.0471, best=-0.0471, s/epoch=0.4]
Fine-tune: 35%|███▌ | 21/60 [00:17<00:31, 1.22it/s, train_loss=0.0392, val_mse=-0.0471, best=-0.0471, s/epoch=0.4]
Fine-tune: 35%|███▌ | 21/60 [00:18<00:31, 1.22it/s, train_loss=0.0691, val_mse=-0.0443, best=-0.0443, s/epoch=0.4]
Fine-tune: 37%|███▋ | 22/60 [00:18<00:31, 1.22it/s, train_loss=0.0691, val_mse=-0.0443, best=-0.0443, s/epoch=0.4]
Fine-tune: 37%|███▋ | 22/60 [00:19<00:31, 1.22it/s, train_loss=0.0431, val_mse=-0.0420, best=-0.0420, s/epoch=0.4]
Fine-tune: 38%|███▊ | 23/60 [00:19<00:30, 1.22it/s, train_loss=0.0431, val_mse=-0.0420, best=-0.0420, s/epoch=0.4]
Fine-tune: 38%|███▊ | 23/60 [00:19<00:30, 1.22it/s, train_loss=0.0339, val_mse=-0.0401, best=-0.0401, s/epoch=0.4]
Fine-tune: 40%|████ | 24/60 [00:19<00:29, 1.22it/s, train_loss=0.0339, val_mse=-0.0401, best=-0.0401, s/epoch=0.4]
Fine-tune: 40%|████ | 24/60 [00:20<00:29, 1.22it/s, train_loss=0.0739, val_mse=-0.0384, best=-0.0384, s/epoch=0.4]
Fine-tune: 42%|████▏ | 25/60 [00:20<00:28, 1.22it/s, train_loss=0.0739, val_mse=-0.0384, best=-0.0384, s/epoch=0.4]
Fine-tune: 42%|████▏ | 25/60 [00:21<00:28, 1.22it/s, train_loss=0.0425, val_mse=-0.0367, best=-0.0367, s/epoch=0.4]
Fine-tune: 43%|████▎ | 26/60 [00:21<00:28, 1.21it/s, train_loss=0.0425, val_mse=-0.0367, best=-0.0367, s/epoch=0.4]
Fine-tune: 43%|████▎ | 26/60 [00:22<00:28, 1.21it/s, train_loss=0.2167, val_mse=-0.0348, best=-0.0348, s/epoch=0.4]
Fine-tune: 45%|████▌ | 27/60 [00:22<00:27, 1.20it/s, train_loss=0.2167, val_mse=-0.0348, best=-0.0348, s/epoch=0.4]
Fine-tune: 45%|████▌ | 27/60 [00:23<00:27, 1.20it/s, train_loss=0.5485, val_mse=-0.0340, best=-0.0340, s/epoch=0.4]
Fine-tune: 47%|████▋ | 28/60 [00:23<00:26, 1.20it/s, train_loss=0.5485, val_mse=-0.0340, best=-0.0340, s/epoch=0.4]
Fine-tune: 47%|████▋ | 28/60 [00:24<00:26, 1.20it/s, train_loss=0.0417, val_mse=-0.0333, best=-0.0333, s/epoch=0.4]
Fine-tune: 48%|████▊ | 29/60 [00:24<00:25, 1.20it/s, train_loss=0.0417, val_mse=-0.0333, best=-0.0333, s/epoch=0.4]
Fine-tune: 48%|████▊ | 29/60 [00:24<00:25, 1.20it/s, train_loss=0.0591, val_mse=-0.0328, best=-0.0328, s/epoch=0.4]
Fine-tune: 50%|█████ | 30/60 [00:24<00:24, 1.20it/s, train_loss=0.0591, val_mse=-0.0328, best=-0.0328, s/epoch=0.4]
Fine-tune: 50%|█████ | 30/60 [00:25<00:24, 1.20it/s, train_loss=0.0275, val_mse=-0.0324, best=-0.0324, s/epoch=0.4]
Fine-tune: 52%|█████▏ | 31/60 [00:25<00:24, 1.21it/s, train_loss=0.0275, val_mse=-0.0324, best=-0.0324, s/epoch=0.4]
Fine-tune: 52%|█████▏ | 31/60 [00:26<00:24, 1.21it/s, train_loss=0.0439, val_mse=-0.0319, best=-0.0319, s/epoch=0.4]
Fine-tune: 53%|█████▎ | 32/60 [00:26<00:23, 1.21it/s, train_loss=0.0439, val_mse=-0.0319, best=-0.0319, s/epoch=0.4]
Fine-tune: 53%|█████▎ | 32/60 [00:27<00:23, 1.21it/s, train_loss=0.0189, val_mse=-0.0314, best=-0.0314, s/epoch=0.4]
Fine-tune: 55%|█████▌ | 33/60 [00:27<00:22, 1.21it/s, train_loss=0.0189, val_mse=-0.0314, best=-0.0314, s/epoch=0.4]
Fine-tune: 55%|█████▌ | 33/60 [00:28<00:22, 1.21it/s, train_loss=0.0454, val_mse=-0.0310, best=-0.0310, s/epoch=0.4]
Fine-tune: 57%|█████▋ | 34/60 [00:28<00:21, 1.21it/s, train_loss=0.0454, val_mse=-0.0310, best=-0.0310, s/epoch=0.4]
Fine-tune: 57%|█████▋ | 34/60 [00:29<00:21, 1.21it/s, train_loss=0.0306, val_mse=-0.0307, best=-0.0307, s/epoch=0.4]
Fine-tune: 58%|█████▊ | 35/60 [00:29<00:20, 1.21it/s, train_loss=0.0306, val_mse=-0.0307, best=-0.0307, s/epoch=0.4]
Fine-tune: 58%|█████▊ | 35/60 [00:29<00:20, 1.21it/s, train_loss=0.0403, val_mse=-0.0304, best=-0.0304, s/epoch=0.4]
Fine-tune: 60%|██████ | 36/60 [00:29<00:19, 1.21it/s, train_loss=0.0403, val_mse=-0.0304, best=-0.0304, s/epoch=0.4]
Fine-tune: 60%|██████ | 36/60 [00:30<00:19, 1.21it/s, train_loss=0.0437, val_mse=-0.0301, best=-0.0301, s/epoch=0.4]
Fine-tune: 62%|██████▏ | 37/60 [00:30<00:19, 1.21it/s, train_loss=0.0437, val_mse=-0.0301, best=-0.0301, s/epoch=0.4]
Fine-tune: 62%|██████▏ | 37/60 [00:31<00:19, 1.21it/s, train_loss=0.0347, val_mse=-0.0299, best=-0.0299, s/epoch=0.4]
Fine-tune: 63%|██████▎ | 38/60 [00:31<00:18, 1.21it/s, train_loss=0.0347, val_mse=-0.0299, best=-0.0299, s/epoch=0.4]
Fine-tune: 63%|██████▎ | 38/60 [00:32<00:18, 1.21it/s, train_loss=0.0346, val_mse=-0.0298, best=-0.0298, s/epoch=0.4]
Fine-tune: 65%|██████▌ | 39/60 [00:32<00:17, 1.21it/s, train_loss=0.0346, val_mse=-0.0298, best=-0.0298, s/epoch=0.4]
Fine-tune: 65%|██████▌ | 39/60 [00:33<00:17, 1.21it/s, train_loss=0.0405, val_mse=-0.0297, best=-0.0298, s/epoch=0.4]
Fine-tune: 67%|██████▋ | 40/60 [00:33<00:16, 1.22it/s, train_loss=0.0405, val_mse=-0.0297, best=-0.0298, s/epoch=0.4]
Fine-tune: 67%|██████▋ | 40/60 [00:34<00:16, 1.22it/s, train_loss=0.0522, val_mse=-0.0296, best=-0.0296, s/epoch=0.4]
Fine-tune: 68%|██████▊ | 41/60 [00:34<00:15, 1.22it/s, train_loss=0.0522, val_mse=-0.0296, best=-0.0296, s/epoch=0.4]
Fine-tune: 68%|██████▊ | 41/60 [00:34<00:15, 1.22it/s, train_loss=0.0383, val_mse=-0.0295, best=-0.0295, s/epoch=0.4]
Fine-tune: 70%|███████ | 42/60 [00:34<00:14, 1.21it/s, train_loss=0.0383, val_mse=-0.0295, best=-0.0295, s/epoch=0.4]
Fine-tune: 70%|███████ | 42/60 [00:35<00:14, 1.21it/s, train_loss=0.0518, val_mse=-0.0295, best=-0.0295, s/epoch=0.4]
Fine-tune: 72%|███████▏ | 43/60 [00:35<00:13, 1.22it/s, train_loss=0.0518, val_mse=-0.0295, best=-0.0295, s/epoch=0.4]
Fine-tune: 72%|███████▏ | 43/60 [00:36<00:13, 1.22it/s, train_loss=0.0437, val_mse=-0.0297, best=-0.0295, s/epoch=0.4]
Fine-tune: 73%|███████▎ | 44/60 [00:36<00:13, 1.22it/s, train_loss=0.0437, val_mse=-0.0297, best=-0.0295, s/epoch=0.4]
Fine-tune: 73%|███████▎ | 44/60 [00:37<00:13, 1.22it/s, train_loss=0.0294, val_mse=-0.0298, best=-0.0295, s/epoch=0.4]
Fine-tune: 75%|███████▌ | 45/60 [00:37<00:12, 1.23it/s, train_loss=0.0294, val_mse=-0.0298, best=-0.0295, s/epoch=0.4]
Fine-tune: 75%|███████▌ | 45/60 [00:38<00:12, 1.23it/s, train_loss=0.0505, val_mse=-0.0300, best=-0.0295, s/epoch=0.4]
Fine-tune: 77%|███████▋ | 46/60 [00:38<00:11, 1.23it/s, train_loss=0.0505, val_mse=-0.0300, best=-0.0295, s/epoch=0.4]
Fine-tune: 77%|███████▋ | 46/60 [00:38<00:11, 1.23it/s, train_loss=0.0616, val_mse=-0.0302, best=-0.0295, s/epoch=0.4]
Fine-tune: 78%|███████▊ | 47/60 [00:38<00:10, 1.23it/s, train_loss=0.0616, val_mse=-0.0302, best=-0.0295, s/epoch=0.4]
Fine-tune: 78%|███████▊ | 47/60 [00:39<00:10, 1.23it/s, train_loss=0.2092, val_mse=-0.0303, best=-0.0295, s/epoch=0.4]
Fine-tune: 80%|████████ | 48/60 [00:39<00:09, 1.24it/s, train_loss=0.2092, val_mse=-0.0303, best=-0.0295, s/epoch=0.4]
Fine-tune: 80%|████████ | 48/60 [00:40<00:09, 1.24it/s, train_loss=0.0439, val_mse=-0.0304, best=-0.0295, s/epoch=0.4]
Fine-tune: 82%|████████▏ | 49/60 [00:40<00:08, 1.23it/s, train_loss=0.0439, val_mse=-0.0304, best=-0.0295, s/epoch=0.4]
Fine-tune: 82%|████████▏ | 49/60 [00:41<00:08, 1.23it/s, train_loss=0.0299, val_mse=-0.0305, best=-0.0295, s/epoch=0.4]
Fine-tune: 83%|████████▎ | 50/60 [00:41<00:08, 1.23it/s, train_loss=0.0299, val_mse=-0.0305, best=-0.0295, s/epoch=0.4]
Fine-tune: 83%|████████▎ | 50/60 [00:42<00:08, 1.23it/s, train_loss=0.0382, val_mse=-0.0306, best=-0.0295, s/epoch=0.4]
Fine-tune: 85%|████████▌ | 51/60 [00:42<00:07, 1.22it/s, train_loss=0.0382, val_mse=-0.0306, best=-0.0295, s/epoch=0.4]
Fine-tune: 85%|████████▌ | 51/60 [00:42<00:07, 1.22it/s, train_loss=0.0267, val_mse=-0.0306, best=-0.0295, s/epoch=0.4]
Fine-tune: 85%|████████▌ | 51/60 [00:42<00:07, 1.19it/s, train_loss=0.0267, val_mse=-0.0306, best=-0.0295, s/epoch=0.4]
Evaluate on the held-out test set#
ft_pred = reg.predict(X_test)
ft_mse, ft_mae, ft_r2 = _metrics(ft_pred, y_test)
if is_main_process:
header = f"{'metric':<10}{'pretrained':>14}{'fine-tuned':>14}{'Δ':>14}"
rule = "=" * len(header)
print()
print(rule)
print(f"Test-set metrics (n_train={len(X_train)}, n_test={len(X_test)})")
print(rule)
print(header)
print("-" * len(header))
print(f"{'MSE ↓':<10}{base_mse:>14.4f}{ft_mse:>14.4f}{ft_mse - base_mse:>+14.4f}")
print(f"{'MAE ↓':<10}{base_mae:>14.4f}{ft_mae:>14.4f}{ft_mae - base_mae:>+14.4f}")
print(f"{'R² ↑':<10}{base_r2:>14.4f}{ft_r2:>14.4f}{ft_r2 - base_r2:>+14.4f}")
print(rule)
====================================================
Test-set metrics (n_train=40, n_test=760)
====================================================
metric pretrained fine-tuned Δ
----------------------------------------------------
MSE ↓ 0.0573 0.0239 -0.0335
MAE ↓ 0.1543 0.1059 -0.0484
R² ↑ 0.8894 0.9540 +0.0646
====================================================
Figure 1 — Predictions + residuals#
Yellow band = spike FWHM; the residual gap should collapse there under fine-tuning while the rest of the panel stays flat.
if is_main_process:
x_grid = np.linspace(-3.0, 3.0, 600).reshape(-1, 1).astype(np.float32)
alphas = [0.1, 0.5, 0.9]
q_base = base.predict(x_grid, output_type="quantiles", alphas=alphas)
q_ft = reg.predict(x_grid, output_type="quantiles", alphas=alphas)
# Quantiles on the test grid so the residual panel can show the
# 10–90% band around zero (a calibration read at a glance).
qt_base = base.predict(X_test, output_type="quantiles", alphas=alphas)
qt_ft = reg.predict(X_test, output_type="quantiles", alphas=alphas)
order = np.argsort(X_test.ravel())
x_sorted = X_test.ravel()[order]
fig1, axes = plt.subplots(2, 2, figsize=(13.5, 8.0), sharex=True, sharey="row", constrained_layout=True)
top = axes[0]
bot = axes[1]
# Same emerald as the classifier tutorial for the "ground truth"
# reference, so the two figures share a visual vocabulary.
TRUTH_COLOR = "#10b981"
for ax, title, q, (mse, r2) in [
(top[0], "Pretrained TabICL", q_base, (base_mse, base_r2)),
(top[1], "Fine-tuned TabICL", q_ft, (ft_mse, ft_r2)),
]:
ax.fill_between(
x_grid.ravel(),
q[:, 0],
q[:, 2],
color="#60a5fa",
alpha=0.25,
label="10–90 % quantile band",
)
ax.plot(x_grid.ravel(), q[:, 1], color="#1d4ed8", lw=2.2, label="predicted median")
ax.plot(x_grid.ravel(), target_fn(x_grid.ravel()), color=TRUTH_COLOR, lw=2.0, ls="--", label="true target")
ax.scatter(
X_train.ravel(),
y_train,
c="#b45309",
edgecolor="white",
s=32,
linewidths=0.8,
label=f"train (n={len(X_train)})",
)
# Shade the FWHM of the sharp spike to flag where the failure mode
# lives. Both panels share the band so the comparison is direct.
ax.axvspan(0.905, 1.095, color="#fde68a", alpha=0.45, zorder=0, label="spike FWHM")
ax.set_title(f"{title}\nMSE={mse:.3f} R²={r2:.3f}", fontsize=12)
ax.tick_params(labelsize=10)
ax.grid(alpha=0.25)
top[0].set_ylabel("y", fontsize=11)
top[0].legend(loc="lower right", framealpha=0.92, fontsize=9)
# Residual panels: predicted − true, with the 10–90% band relative to
# the predicted median so the shaded region is centered on zero.
for ax, title, pred, qt in [
(bot[0], "Residuals — pretrained", base_pred, qt_base),
(bot[1], "Residuals — fine-tuned", ft_pred, qt_ft),
]:
residual = pred - y_test
lo = (qt[:, 0] - qt[:, 1])[order]
hi = (qt[:, 2] - qt[:, 1])[order]
ax.fill_between(x_sorted, lo, hi, color="#60a5fa", alpha=0.22, label="10–90 % band (centered)")
ax.scatter(X_test.ravel(), residual, c="#334155", s=10, alpha=0.65, label="residual (pred − y)")
ax.axhline(0, color="black", lw=0.8)
ax.axvspan(0.905, 1.095, color="#fde68a", alpha=0.45, zorder=0, label="spike FWHM")
ax.set_title(title, fontsize=12)
ax.set_xlabel("x", fontsize=11)
ax.tick_params(labelsize=10)
ax.grid(alpha=0.25)
bot[0].set_ylabel("residual", fontsize=11)
bot[0].legend(loc="lower right", framealpha=0.92, fontsize=9)
# sharey="row" already aligns the two residual panels; just widen the
# limits symmetrically around zero so max |residual| from either model
# fits in both.
y_res_lim = max(np.abs(base_pred - y_test).max(), np.abs(ft_pred - y_test).max())
bot[0].set_ylim(-y_res_lim * 1.1, y_res_lim * 1.1)
fig1.suptitle("Predictions + residuals: pretrained vs. fine-tuned", fontsize=14)
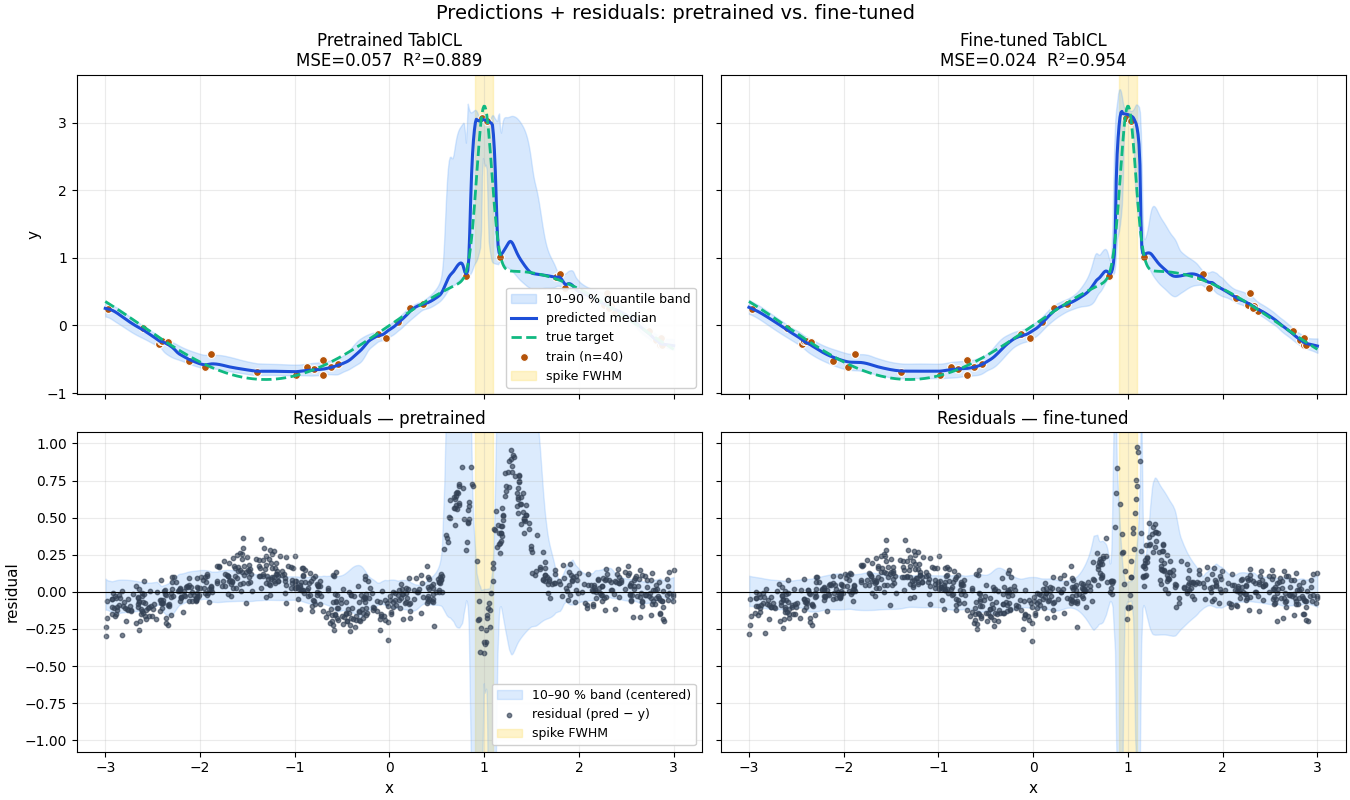
Figure 2 — Training dynamics + metric comparison#
Left: val MSE per epoch; dashed line = pretrained floor, star = best epoch kept by the safety net. Right: test-set MSE / MAE / R² bars.
if is_main_process and history["epoch"]:
fig2, (ax_tr, ax_bar) = plt.subplots(1, 2, figsize=(12.8, 4.8), constrained_layout=True)
ep = history["epoch"]
val_mse = history["val_mse"]
ax_tr.plot(ep, val_mse, "o-", color="#0f766e", lw=2.0, markersize=5, label="fine-tuning: val MSE")
ax_tr.axhline(
base_val_mse,
ls="--",
color="#64748b",
lw=1.5,
label=f"pretrained baseline ({base_val_mse:.3f})",
)
best_idx = int(np.nanargmin(val_mse))
ax_tr.scatter(
[ep[best_idx]],
[val_mse[best_idx]],
marker="*",
s=220,
color="#f59e0b",
edgecolor="black",
linewidths=0.8,
zorder=5,
label=f"best epoch ({val_mse[best_idx]:.3f} @ epoch {ep[best_idx]})",
)
ax_tr.set_xlabel("epoch")
ax_tr.set_ylabel("validation MSE (lower is better)")
ax_tr.set_title("Validation metric across fine-tuning epochs")
ax_tr.grid(alpha=0.3)
ax_tr.legend(fontsize=9, loc="upper right")
metric_names = ["MSE ↓", "MAE ↓", "R² ↑"]
base_vals = [base_mse, base_mae, base_r2]
ft_vals = [ft_mse, ft_mae, ft_r2]
x_pos = np.arange(len(metric_names))
w = 0.38
bars_b = ax_bar.bar(x_pos - w / 2, base_vals, w, color="#64748b", label="pretrained")
bars_f = ax_bar.bar(x_pos + w / 2, ft_vals, w, color="#0f766e", label="fine-tuned")
for bars, vals in [(bars_b, base_vals), (bars_f, ft_vals)]:
for rect, v in zip(bars, vals):
y_anchor = v + (0.02 if v >= 0 else -0.04)
ax_bar.text(
rect.get_x() + rect.get_width() / 2,
y_anchor,
f"{v:.3f}",
ha="center",
va="bottom" if v >= 0 else "top",
fontsize=8,
)
ax_bar.set_xticks(x_pos)
ax_bar.set_xticklabels(metric_names)
ax_bar.set_title("Test-set metrics: pretrained vs. fine-tuned")
ax_bar.set_ylabel("metric value")
ax_bar.axhline(0, color="black", lw=0.5)
ax_bar.grid(alpha=0.25, axis="y")
ax_bar.legend(fontsize=9, loc="upper right")
fig2.suptitle("Training dynamics & test-set gains", fontsize=13)
plt.show()

Total running time of the script: (1 minutes 1.611 seconds)